

For a webpage to be indexed in search results, it must first be crawled by a search engine’s crawlers. And Google makes it easy to see when a URL was last crawled.
There are a few different approaches to finding this information and several steps you’ll want to take if your URLs aren’t getting crawled and indexed correctly.
Checking Manually with the URL Inspection Tool
First, you’ll want to copy the URL address for the webpage you want to analyze. Next, head over to Google Search Console (GSC).
Once you’re logged into GSC, you’ll see a search bar at the top of the screen, also known as the URL Inspection Tool. Paste your URL into this search bar and hit enter:
Then you’ll receive a report (it might take a few seconds to load):
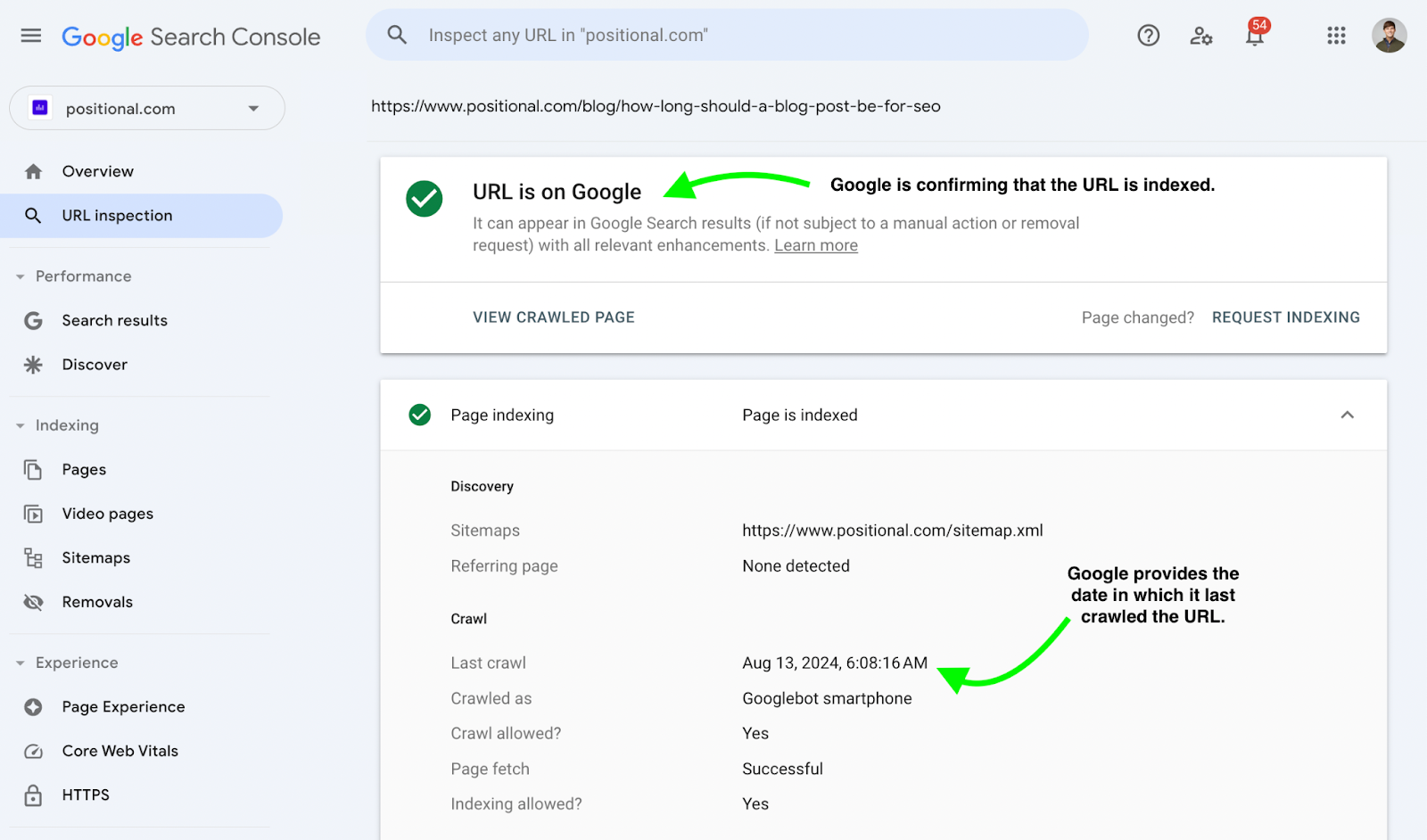
As shown above, Google will first confirm whether the URL is currently indexed, and then it will show you the last crawl date and time in the Page Indexing expansion window.
If your URL hasn’t been crawled yet, the result will look something like this:

In some cases, Google will crawl a URL but not index it:
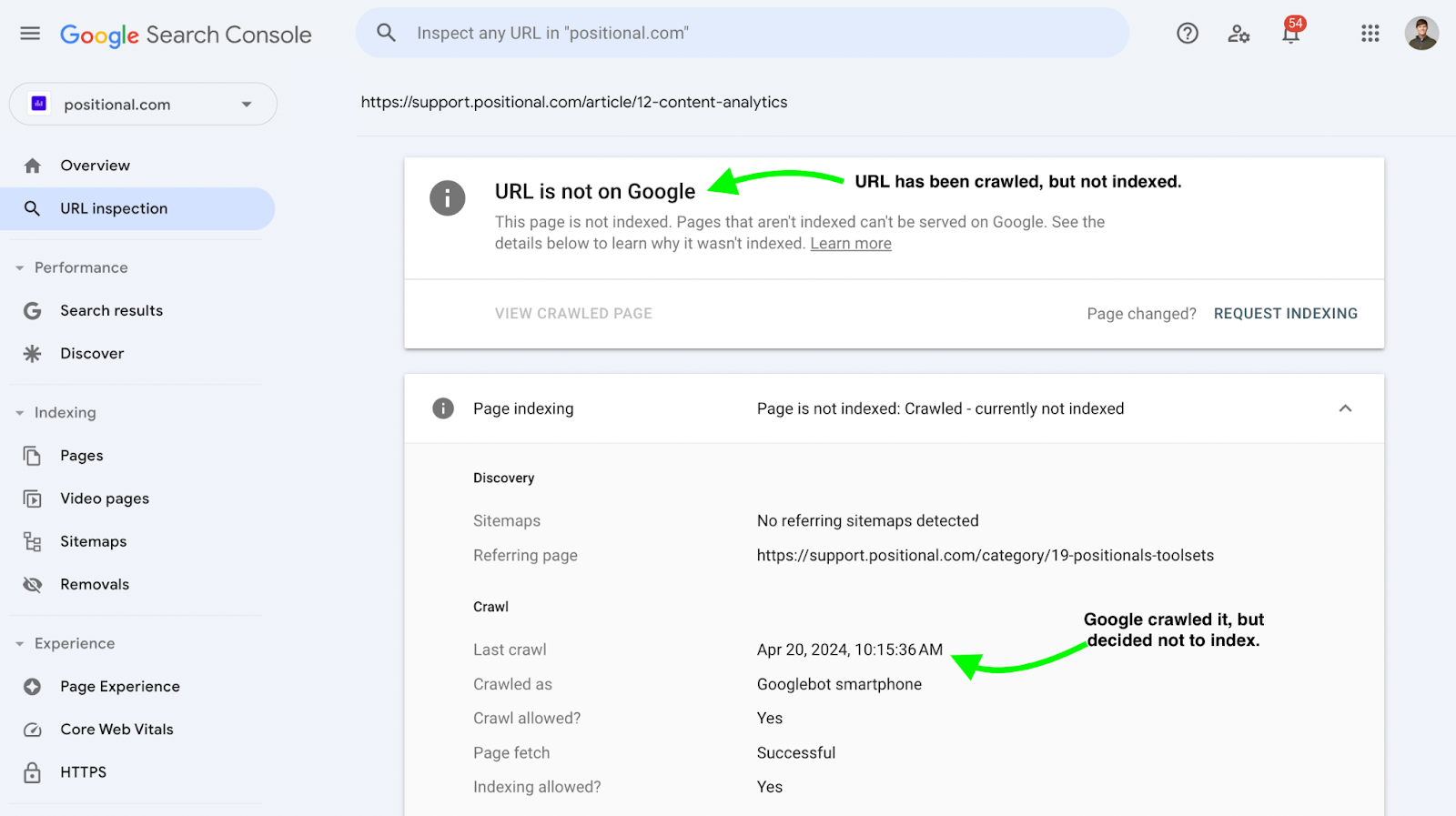
Using Request Indexing
You can prompt Google to crawl your URL, whether it has been newly created and not crawled yet or you’d just like Google to re-crawl a URL.
Click the Request Indexing button:
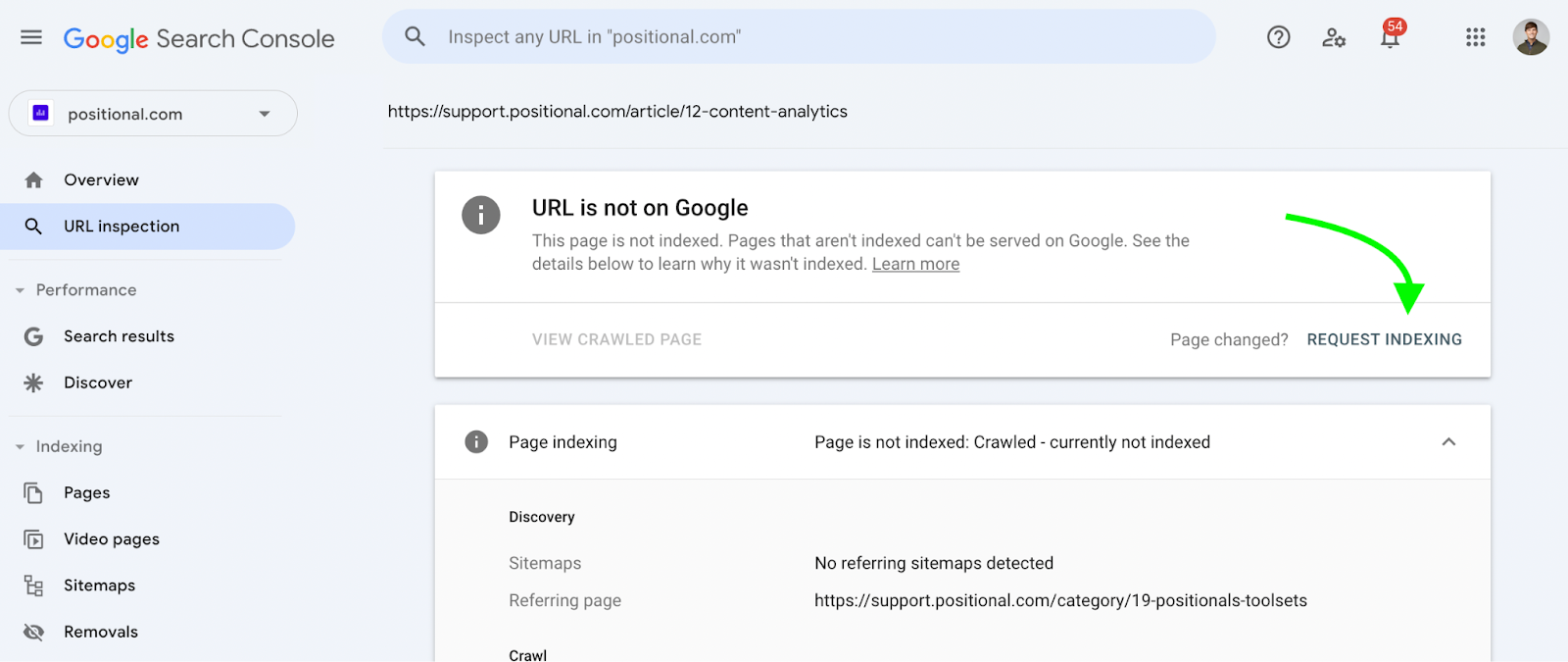
Google states that it might take anywhere from a few days to weeks for the URL to be crawled or re-crawled using this method. However, with our website, Google will typically initiate the crawl within 24 hours of my request for indexing.
There’s no need to click on Request Indexing multiple times — that won’t make Google crawl the URL faster, and Google limits the number of times you can click on it.
Using the API to Check
If you’re dealing with a large number of URLs, and you want to check the last crawl date for all of them, I would recommend using the Search Console URL Inspection API.
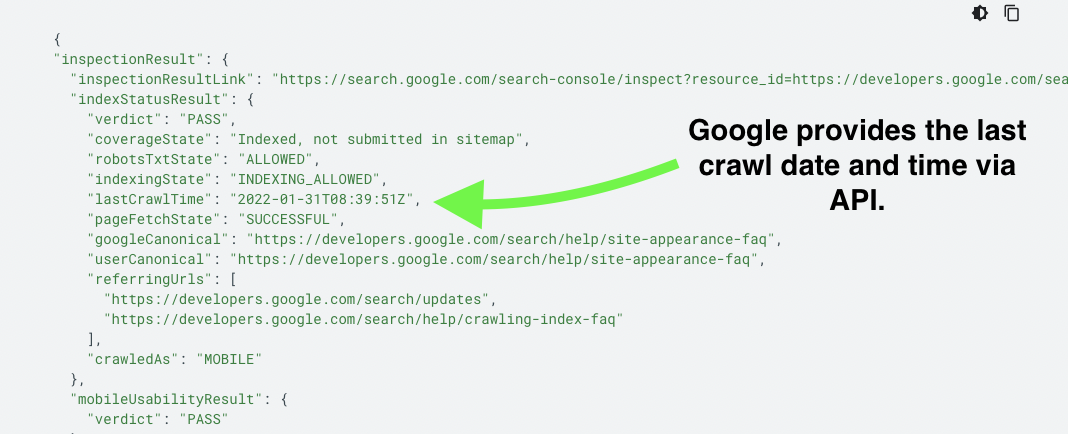
Using the API, you can check as many as 2,000 URLs per day or 600 per minute.
Check the Log Files
If you need to check a very large number of URLs, more than 2,000 per day, and the API is limiting you, another approach would be to check the log files directly.
Every time Google’s Googlebot requests a copy of your webpage, it will make a request to the server. You’ll need to extract the log files and then filter them to find references to Googlebot.
Here is what this request might look like:
You can identify the URL requested directly from the log files — in this case, it’s a URL on the path /my-URL.
Additional Crawling Data Available in GSC
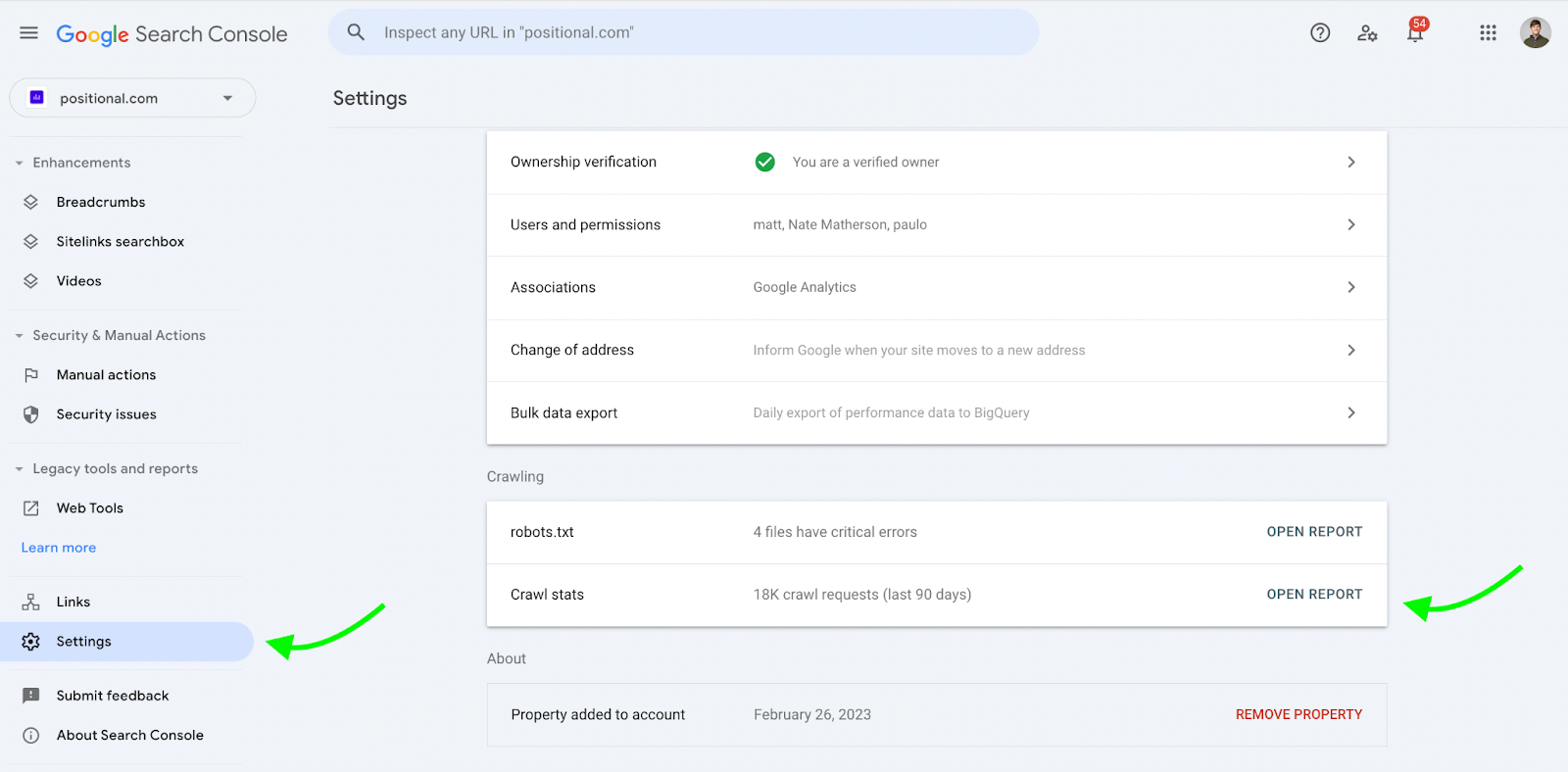
In GSC, you can view your website's crawling data.
It is a little hidden. Go to Settings and then click on Open Report next to Crawl Stats:
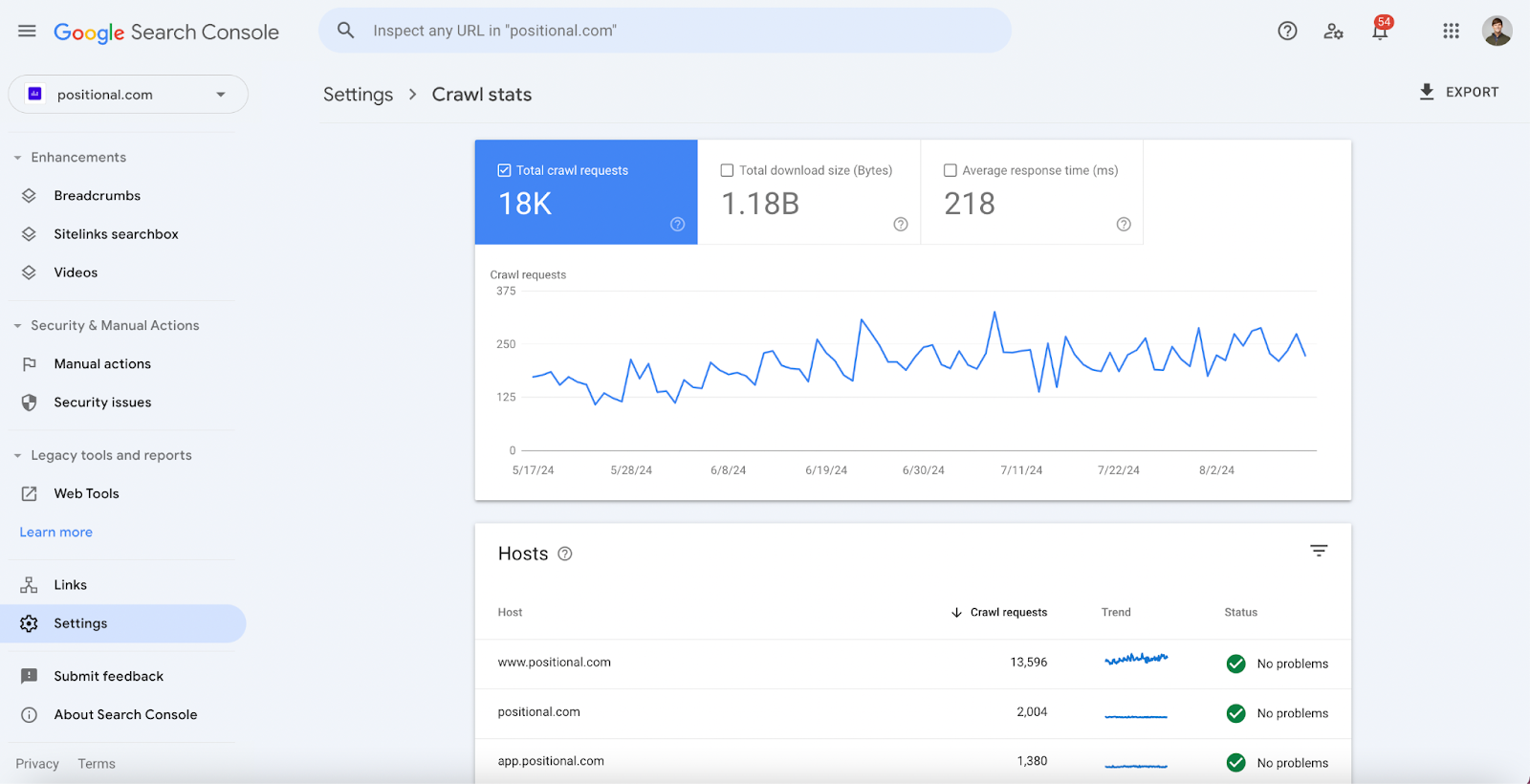
Google provides high-level data, including the total number of crawl requests, or the number of pages that Google has tried to crawl on a daily basis:
If you click into one of the hosts, you can get more granular data:
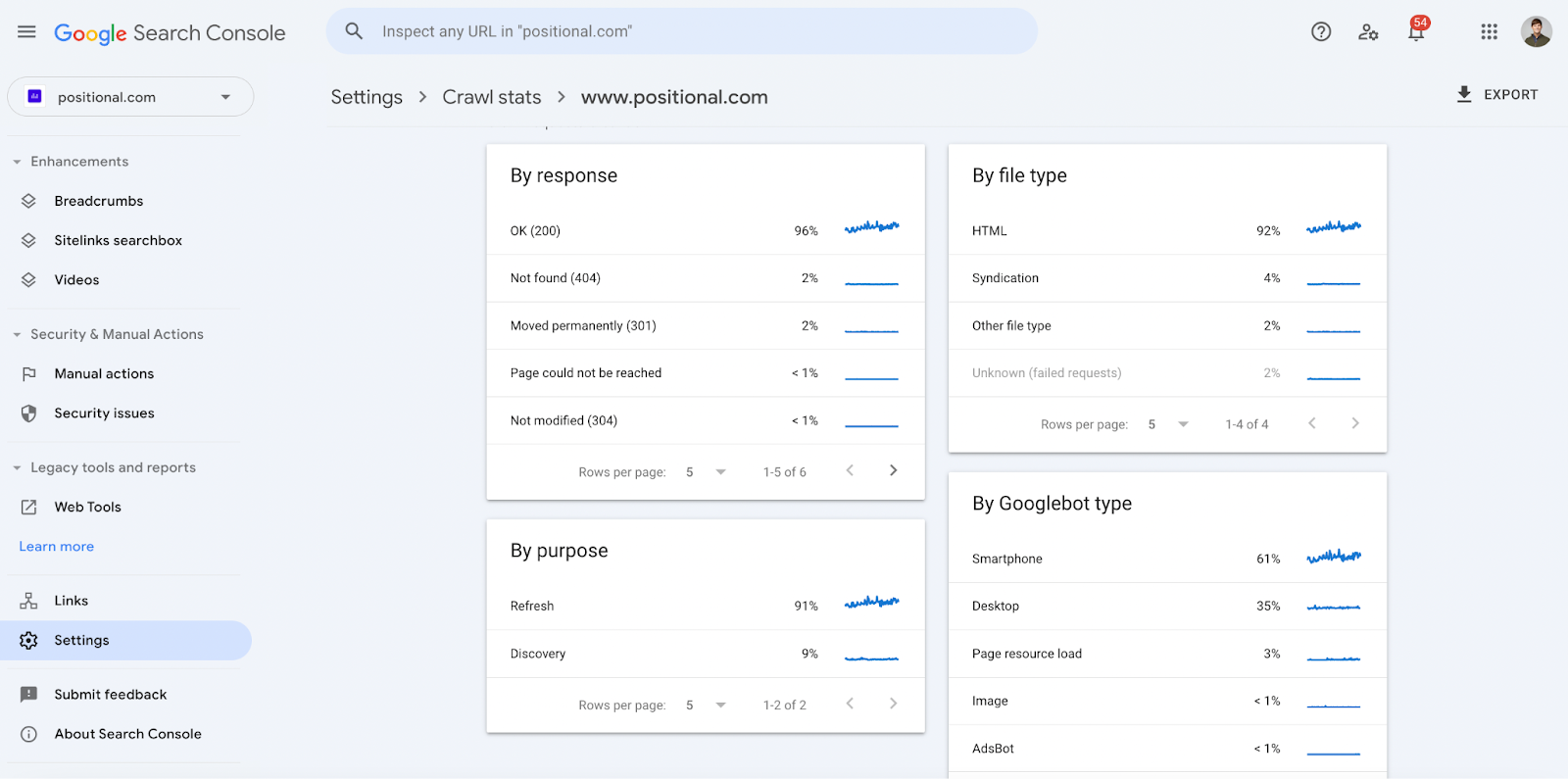
I find the By Purpose section interesting. For example, Google will tell you which URLs they’ve re-crawled for refresh:

Google will also tell you which URLs they’ve crawled for the first time or that were recently discovered. All of the data is exportable, so if you don’t want to use the API, you could always export it manually to a spreadsheet.
Google will provide you with a breakdown of the different types of crawlers used (for example, mobile or desktop) and response codes (for example, 404 or 301) for each request.
Checking Indexing with Site:
If you want to check for indexing without logging into GSC, another quick approach is to use the site: search modifier.
Simply go to Google, enter site:[URL], and then hit enter:
If your URL appears in a search engine results page (SERP), that would indicate that your URL has been crawled and indexed.
Troubleshooting Crawling and Indexing Issues
If you have a very large website with millions of webpages or a medium-sized website that changes frequently, you might need to worry about your crawl budget, or the number of webpages that Google will crawl from your website.
The vast majority of website owners do not need to worry about crawl budget.
That being said, if you’re concerned about crawl budget, you could take steps to improve your website's performance, server response times, and site architecture. (We’ve written extensively about crawl budget.)
If you’re experiencing indexing issues, that might be a result of crawl budget constraints, but for most of the websites I look at, indexing issues are caused by a host of other factors.
For example, if you’ve published a large number of low-quality or thin webpages, you might be seeing the “Discovered - currently not indexed” issue being reported in GSC. In other words, Google has seen your webpages but decided not to crawl them, most often due to content quality issues. You may need to remove unhelpful content from your website and work to improve the helpfulness of the remaining pages.
The same could be said for the “Crawled - currently not indexed” issue. In this case, Google has crawled your webpage but decided not to index it. Again, this is most often due to quality issues.
If you haven’t already submitted your sitemap in GSC, you should do so to allow Google to find all your URLs more efficiently and ensure that nothing is missed.
And don’t forget to think critically about your internal linking strategy. Internal links are helpful for folks visiting your website, but they also help Google’s crawlers to understand how your website is organized, which webpages are important, and which webpages they might want to crawl or re-crawl next.
Final Thoughts
There are several different ways to find out when Google last crawled your website and its specific webpages.
If you need to check only a small number of URLs, I would recommend starting with the URL Inspection tool.
If you need to check a large number of webpages regularly, you should use the API or set up a process for analyzing your log files.
If you don’t want to use the API or review log files but want to check a large number of webpages quickly, you can export the raw data into a spreadsheet by opening the report titled Crawl Stats in GSC.



